
 Számítógépes rendszerek az embernél jobban teljesítenek olyan egyértelmű feladatokat, mint a sakk vagy az időjárás-előrejelzés, árnyaltabb, többféleképpen értelmezhető problémák kezelése viszont egyáltalán nem az ő világuk: bőven lemaradva kullognak mögöttünk.
Számítógépes rendszerek az embernél jobban teljesítenek olyan egyértelmű feladatokat, mint a sakk vagy az időjárás-előrejelzés, árnyaltabb, többféleképpen értelmezhető problémák kezelése viszont egyáltalán nem az ő világuk: bőven lemaradva kullognak mögöttünk.
Nehezen, vagy egyáltalán nem boldogulnak azokkal az esetekkel, amikor különböző forrásokat összekombinálva kell rátalálniuk a helyes megoldásra. Jócskán akad tanulnivalójuk: a nyelvet egyrészt jelentéstanilag, szövegkörnyezetükben értelmezve szavakat és mondatokat, másrészt az ember által hosszú évek alatt elsajátított kulturális háttérismeretekkel, de legalább azok egy részével rendelkezve kellene megközelíteniük.
Jelentésalapú rendszerek
A számítástudomány egyik legnagyobb kihívása a humán beszédet, nyelveket értő gépek fejlesztése és az ehhez kapcsolódó gépi tanulás (machine learning). A világháló elterjedésével szaporodnak az ilyen irányú kezdeményezések: a web temérdek szöveges dokumentumával ideális terep adatok strukturált ontológiákba (fogalmak és kapcsolatok formális leírásokká) rendezésére. A WWW kidolgozásában oroszlánrészt vállalt Sir Tim Berners-Lee bő évtizede dolgozik a nyelv gépi értelmezéséhez nélkülözhetetlen ontológiákon nyugvó tetszetős elméleti konstrukció, a szemantikus web gyakorlati megvalósításán.
A hatékonyabb hardverek és szoftverek, a webes adatmennyiség drasztikus növekedése felgyorsította a jelentésalapú technológiák fejlődését. Cégek, felsőoktatási intézmények, kutatóintézetek sokasága foglalkozik a témakörrel.
Az IBM Watsonját kérdés-felelet kvízjátékokra, például a népszerű Jeopardy!-ra tervezték. A QA (Question Answering) rendszer már jelenlegi állapotában is komoly történelmi, kulturális és sportismeretekkel rendelkezik, egyre jobban kapisgálja a feltett kérdéseket.
Az egyelőre döcögő Google a négyzeten (Squared) keresőszolgáltatás találati lista helyett rendszerezett formában, táblázatban foglalja össze a kutakodás eredményét, hivatkozásokat és információkat. Jó hír, hogy egyre inkább érti a jelentésalapú kategóriákat (Egyesült Államok elnökei, sajtok, bolygók stb.).
NELL
Valószínűleg a pittsburghi Carnegie Mellon Egyetem (CMU) NELL-je (Never-ending Language Learning), a hét minden napján, napi 24 órában, örökké nyelvet tanuló rendszer a leginnovatívabb megközelítés: automatizáltabb, mint a többiek, amelyek inkább passzívan, folyamatos emberi beavatkozás mellett próbálnak szert tenni ismeretekre. Január elején állt működésbe; a híres egyetem Gépi Tanulás Tanszékén, Tom M. Mitchell által irányított fejlesztést a DARPA és a Google támogatja, a kivitelezéshez nélkülözhetetlen szuperszámítógép klasztert a Yahoo szolgáltatja.
Tervezői változatos kategóriákat érintő alapismereteket töltöttek adatbázisába, majd „rászabadították” a webre, hogy magától tanuljon, folyamatosan és sokáig gyűjtse, halmozza egymásra az ismereteket, igyekezzen strukturálatlan adatokból strukturált információt kinyerni, úgy szert tenni valamilyen szintű tudásra, ahogy mi tesszük. Eddig még egyetlen számítógép sem volt képes rá, így NELL küldetése valóban úttörő.
Xavi és az FC Barcelona
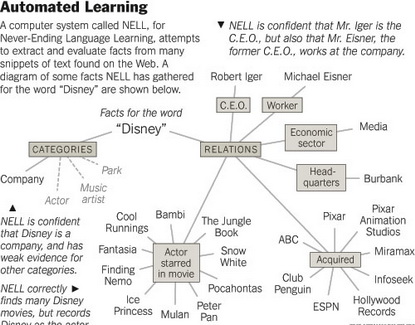 A kezdeti input 280 kategóriát (személy, sportcsapat, gyümölcs, érzelem stb.), szintén 280 kategóriák közti kapcsolatot ((csapatban játszani (sportoló, sportcsapat), hangszeren játszani (zenész, hangszer)) definiáló ontológiából, kategóriánként és kapcsolatonként 15-15 példából (a boldogság érzelem stb.) állt. Mintegy 500 millió honlapból próbál szócsoportokat, mondatokat kivonatolni és osztályozni, szabályokra rájönni, tanuláshoz hasznos szövegmintákat találni, a szövegmintákból kategóriákba sorolható újabb elemeket, különböző kategóriák elemei közti újabb kapcsolatokat megismerni: például „Barack Obama” személy és politikus, míg egy másik példa, „Xavi” és „FC Barcelona” a „csapatban játszani” kapcsolatot szemlélteti. A helyes tényállást nagy valószínűséggel még akkor is kikövetkezteti, ha soha nem olvasta, hogy Xavi az FC Barcelona sportolója.
A kezdeti input 280 kategóriát (személy, sportcsapat, gyümölcs, érzelem stb.), szintén 280 kategóriák közti kapcsolatot ((csapatban játszani (sportoló, sportcsapat), hangszeren játszani (zenész, hangszer)) definiáló ontológiából, kategóriánként és kapcsolatonként 15-15 példából (a boldogság érzelem stb.) állt. Mintegy 500 millió honlapból próbál szócsoportokat, mondatokat kivonatolni és osztályozni, szabályokra rájönni, tanuláshoz hasznos szövegmintákat találni, a szövegmintákból kategóriákba sorolható újabb elemeket, különböző kategóriák elemei közti újabb kapcsolatokat megismerni: például „Barack Obama” személy és politikus, míg egy másik példa, „Xavi” és „FC Barcelona” a „csapatban játszani” kapcsolatot szemlélteti. A helyes tényállást nagy valószínűséggel még akkor is kikövetkezteti, ha soha nem olvasta, hogy Xavi az FC Barcelona sportolója.
Jelenleg 390 ezer elemnél, 87 százalék pontosságnál. A kategóriák és a kapcsolatok száma – az adatbázis, vagy szebben kifejezve tudásbázis – szintén folyamatosan nő. Minél nagyobb, minél több a hasznos ismeret, annál könnyebb finomhangolni NELL tanulóalgoritmusát, és így a keresés egyre gyorsabb, pontosabb lesz, miközben a rendszer folyamatosan korrigálja tévedéseit.
Többféleképpen olvas: például a „Pikes Peak” (Pikes csúcs) szerkezet két szava egyaránt nagybetűvel kezdődik, és mivel a második „csúcs”, valószínűleg hegyről van szó. A következtetéshez egyrészt különböző szövegekben vizsgálja a Pikes Peak, illetve hasonló szókapcsolatok szövegkörnyezetét. Szerencsére eleve úgy tervezték, hogy szabályhierarchiákat alkalmazva, a legeltérőbb kontextusokban is elboldoguljon nüánszokkal, két- és többértelműséggel, ami azonban nem mindig sikerül…
Tévedni gépi dolog
Mitchell érdekes példával hívja fel a figyelmet NELL hiányosságaira: „a lány elkapta a pöttyös pillangót” (the girl caught the butterfly with the spots”) és „a lány hálóval kapta el a pillangót” („the girl caught the butterfly with the net”) angol eredetijei hasonló mondatok, de a gépet mégis összezavarják. A humán olvasónak egyértelmű, hogy a lányok általában nem pöttyösek, viszont nyilvánvalóan ők fogják a hálót, tehát a „pötty” csak a pillangóval, a „háló” csak a lánnyal kapcsolható össze jelentéstanilag. NELL számára annál kevésbé, és pontosan ezeket a tévedéseket elkerülendő tanul a végtelenig.
Ilyenkor kell segíteni neki – az első hat hónapban teljesen automatikusan működött, viszont a kategóriák és a kapcsolatok negyedével komoly gondjai támadtak. A kutatók összegyűjtötték a kirívó sületlenségeket, amiket ismét átnézettek a rendszerrel.
Mitchell egy hibamintára lett különösen figyelmes: NELL a „sütött élelmiszerek” (kenyér, torták, sütemények stb.) kategóriába sorolta az internetes sütiket (cookies) is. A tévedés lavinát indított el: a gép a „töröltem a fájlokat” szintén süteményként értelmezte, és így tovább. A kutató a süti probléma korrigálását követően, NELL-t „visszaparancsolta a sütőiskolába.”
Mitchell szerint a teljesen automatizált tanulás lenne az optimális, de egyelőre még nem tartunk ott. Aggodalomra azonban semmi ok, hiszen általában az ember sem egyedül tanul.




